1. Baseline RAG
Retrieval-Augmented Generation (RAG) represents a paradigm shift in information retrieval and text generation by integrating external retrieval mechanisms into large language models (LLMs). The Baseline RAG, which was considered the state-of-the-art in 2023, follows a straightforward architecture that combines a retriever and a generator to improve the accuracy and reliability of generated responses.
1.1 Architecture
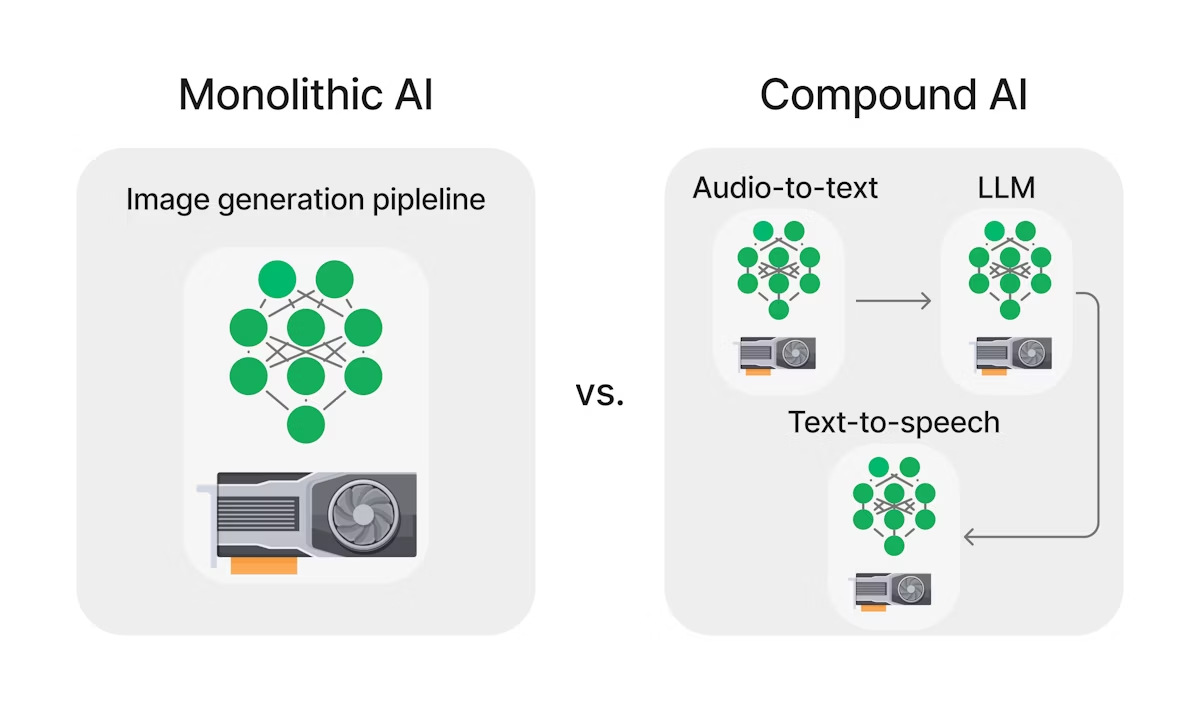
The Baseline RAG consists of two key components:
- Retriever: This component is typically implemented using a search engine or a vector database. It is responsible for retrieving the most relevant Top-K documents based on the user’s query.
- Generator: The generator, usually a large language model (LLM), takes the retrieved documents as input and synthesizes a coherent response.
1.2 Workflow
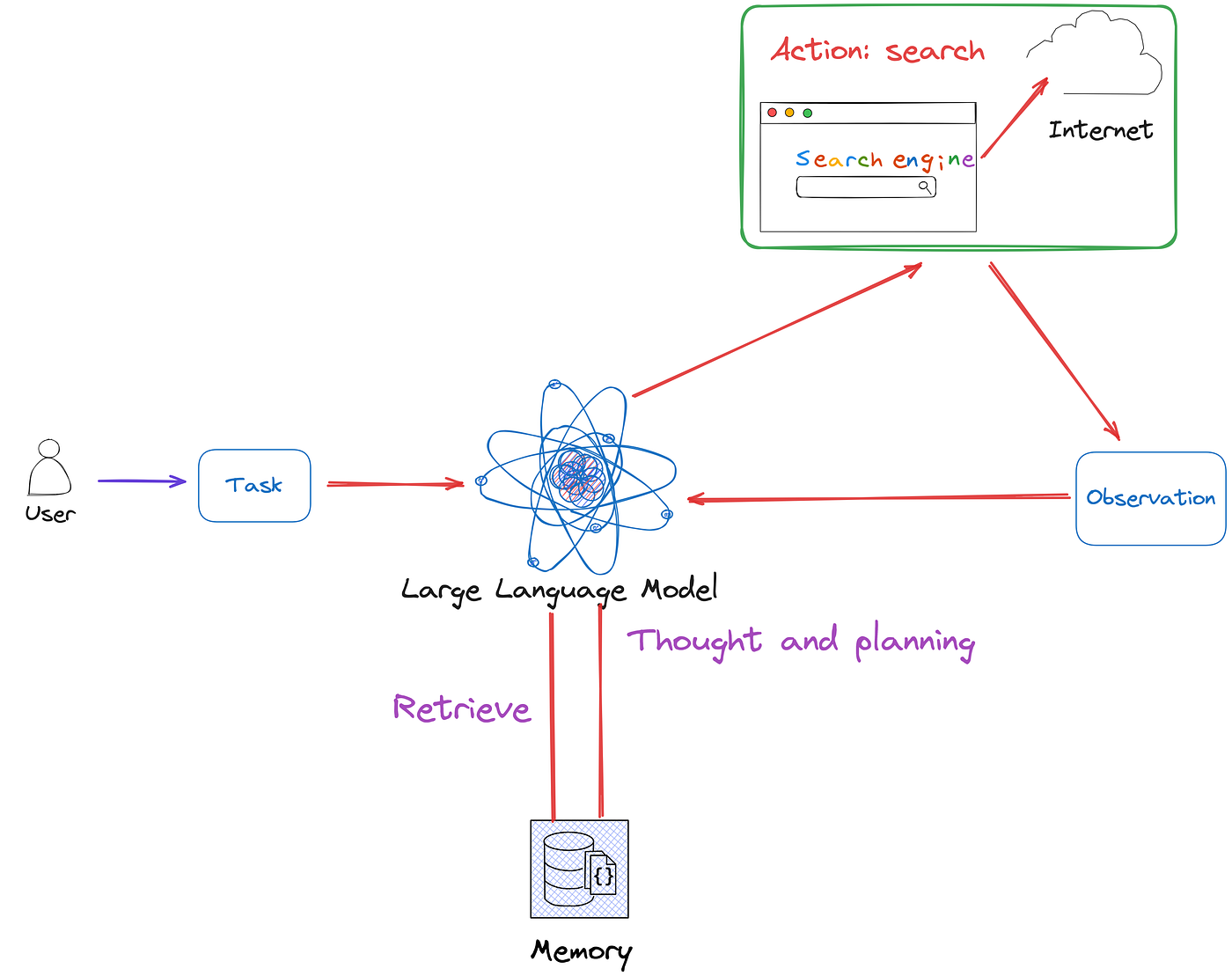
The process of response generation in Baseline RAG follows these steps:
- User Query: The system receives a user’s input query.
- Retrieval: The retriever searches for the Top-K most relevant documents from an indexed knowledge base or vector database.
- Augmentation: The retrieved documents are appended to the system prompt provided to the LLM.
- Generation: The LLM processes the user query along with the retrieved information to generate a response.
- Response Output: The system returns a natural language response to the user, integrating relevant details from the retrieved documents.
1.3 Motivation & Advantages
Baseline RAG was primarily developed to mitigate key issues in traditional LLMs and information retrieval systems:
- Hallucination Mitigation: By incorporating retrieved knowledge from external sources, the LLM is less likely to generate hallucinated or incorrect information.
- Combating Staleness: Since the LLM’s internal knowledge is static and limited by its training data, retrieval allows for the incorporation of updated and relevant information from external sources.
- Bridging the Gap Between Search and Understanding: Traditional search engines return links or documents, leaving the user to extract information manually. RAG automates this process by synthesizing direct answers.
1.4 Perspectives on Baseline RAG
There are two primary ways to conceptualize the Baseline RAG framework:
- LLM-Centric View: The primary advantage is enhancing the LLM’s reliability by supplementing its responses with retrieved knowledge, reducing hallucination and stale information.
- Information Retrieval-Centric View: Traditional search engines return a set of relevant documents, requiring the user to interpret the information. By appending an LLM, RAG effectively automates comprehension and synthesis, turning document retrieval into direct answer generation.
1.5 Evolution from Traditional Search
Before RAG, enterprise search systems primarily relied on keyword-based retrieval or semantic search to return relevant documents. The Baseline RAG model marked a fundamental improvement by integrating LLMs to:
- Extract relevant information from retrieved documents.
- Generate a cohesive, structured answer rather than a simple list of search results.
- Improve accessibility and usability by reducing the cognitive load on users.
1.6 Summary
By 2023, Baseline RAG had become a widely adopted standard, particularly in enterprise search applications, chatbots, and knowledge retrieval systems. It represented a logical evolution in information retrieval, bridging the gap between search systems and generative AI by allowing LLMs to read, interpret, and synthesize information into meaningful responses. While this approach brought significant advantages, it also laid the groundwork for further improvements in retrieval quality, query expansion, and hallucination mitigation, leading to more advanced RAG architectures in subsequent years.
2. Challenges in RAG

Retrieval-Augmented Generation (RAG) represents a significant evolution in information retrieval systems, integrating Large Language Models (LLMs) with traditional search mechanisms to generate coherent and contextual answers. However, despite its advancements, RAG still faces several critical challenges that hinder its reliability and effectiveness.
2.1. Hallucination and Unreliable Answers
One of the primary issues in RAG systems is hallucination, where the LLM generates false or misleading information. This occurs because LLMs have a parametric memory, which consists of knowledge stored in their model weights during pre-training. If the retriever fails to fetch relevant documents, the LLM may resort to generating responses from its internal memory, which might be outdated or incorrect. Worse, if neither the retrieved documents nor the parametric memory contains the answer, the LLM may fabricate information rather than admit uncertainty. This behavior makes RAG systems unpredictable, especially in high-stakes applications like legal, medical, or financial domains.
2.2. Limitations of the Retriever
While RAG improves upon traditional search by summarizing retrieved documents, its effectiveness depends on the quality of the retriever. Standard retrievers, such as vector databases or keyword-based search engines, may return irrelevant, incomplete, or poorly ranked results. This issue is exacerbated when dealing with complex queries requiring multi-hop reasoning across different sources. If the retriever fails to fetch high-quality documents, the LLM’s response quality deteriorates, leading to incorrect or misleading answers.
2.3. Query Framing and Reformulation Issues
A common challenge in RAG systems is how queries are framed and interpreted. Many enterprise users lack the expertise to craft optimal queries that lead to high-quality retrieval. Poorly framed queries may retrieve non-relevant documents, forcing the LLM to generate suboptimal responses. Additionally, different retrieval techniques, such as keyword search, semantic search, and hybrid search, yield varying results, requiring sophisticated query expansion and reformulation strategies to improve search precision.
2.4. Ineffective Chunking for Retrieval
Information retrieval in RAG is often dependent on how source documents are chunked before being stored in a vector database. Traditional chunking methods, such as fixed-size or sentence-based chunking, may disrupt the semantic coherence of information, leading to fragmented retrieval results. This fragmentation affects the LLM’s ability to generate comprehensive answers, as key contextual information may be split across multiple chunks, reducing the effectiveness of retrieval.
2.5. Retrieval from Multi-source Data
Many enterprises require RAG systems to retrieve information from structured databases, internal documentation, and web sources simultaneously. However, integrating these diverse data sources presents challenges in retrieval accuracy, ranking, and merging information. Inconsistent formatting, varying levels of detail, and conflicting information across sources further complicate the retrieval and synthesis process.
2.6. Over-reliance on LLM Parametric Memory
Enterprises deploying RAG systems often prefer responses based solely on retrieved documents rather than the LLM’s internal parametric memory. However, enforcing this restriction is difficult. Even when explicitly instructed to rely only on retrieved information, LLMs tend to default to their internal knowledge if the search results are insufficient. This behavior results in responses that may contradict the latest documents or company policies.
2.7. Computational Costs and Latency
While RAG enhances retrieval, it also increases computational overhead. Running an LLM alongside a retriever incurs additional processing time, particularly when performing multi-step retrieval or query expansion. The need for dynamic reranking, hybrid search, and iterative document retrieval further compounds latency. For real-time applications, balancing accuracy with response speed remains a key challenge.
2.8. Strategies for Mitigating These Challenges
To address these challenges, various techniques are being explored:
- Hallucination Mitigation: Implementing back-referencing mechanisms that require LLMs to cite sources for every statement.
- Query Quality Improvement: Using LLM-assisted query rewriting and knowledge graphs to refine search queries dynamically.
- Optimal Chunking Techniques: Employing AI-driven chunking strategies like propositional decomposition (e.g., DenX Retrieval) to improve document segmentation.
- Hierarchical Retrieval Models: Structuring multi-source data into knowledge graphs or hierarchical retrieval pipelines to improve information synthesis.
- Agentic RAG Systems: Dynamically allocating computational resources based on query complexity to balance accuracy and efficiency.
While RAG represents a powerful evolution in AI-driven search, these persistent challenges highlight the need for ongoing advancements in retrieval algorithms, chunking strategies, and hallucination mitigation techniques. Enterprises must continuously refine their RAG implementations to ensure accuracy, reliability, and scalability.
3. Hallucination Mitigation in RAG
One of the core challenges in Retrieval-Augmented Generation (RAG) is hallucination, where the language model generates incorrect, misleading, or unverifiable information. This occurs when an LLM synthesizes responses based on incomplete, outdated, or absent knowledge. Since LLMs have parametric memory, knowledge embedded in their pre-trained weights, they may attempt to answer questions even when relevant retrieved documents do not contain the necessary information.
A primary method to mitigate hallucinations is enforcing back-referencing, where every generated statement is explicitly linked to supporting evidence from the retrieved search results. This approach forces the LLM to cite sources, reducing the risk of fabrication. Systems like Perplexity AI have pioneered this technique by ensuring responses include references to specific documents, allowing users to verify claims and track information provenance.
Other techniques include:
- Strict Retrieval Dependency: Configuring the system so the LLM only generates responses using retrieved documents, rather than its pre-trained knowledge. This is achieved by suppressing parametric memory usage when external data is available.
- Citation Enforcement: Implementing response validation mechanisms that require the model to justify each claim with a corresponding reference from retrieved documents before outputting an answer.
- Abstention Strategies: Designing the model to refrain from answering if sufficient supporting evidence is not retrieved. This can be reinforced through confidence thresholds, ensuring responses are only provided when the retrieved documents contain clear and verifiable information.
- Post-hoc Fact-Checking: Using a secondary verification model or heuristic scoring method to assess the alignment of generated responses with retrieved sources, flagging inconsistencies or hallucinations.
While these techniques significantly improve response reliability, they introduce trade-offs in latency and computational cost. Ensuring hallucination mitigation remains effective without degrading system performance is an ongoing area of research and development in enterprise RAG implementations.
4. Query Quality & Expansion in RAG
One of the fundamental weaknesses in Retrieval-Augmented Generation (RAG) is its dependency on the quality of user queries. Since retrieval systems rely on queries to fetch relevant documents, poorly framed queries significantly degrade performance. Unfortunately, most human users do not construct optimal queries, making query expansion and refinement essential for improving retrieval effectiveness.
Query expansion involves modifying, elaborating, or supplementing the original query to increase its likelihood of retrieving relevant results. Several techniques have emerged over the years to enhance queries before they pass through the retrieval system:
- Linguistic Expansion: Simple lexical techniques such as synonym expansion can improve recall by incorporating alternative terms. For example, a query containing “car” may be expanded to include “automobile” or “vehicle.”
- Knowledge Graph Augmentation: Expanding queries by fetching neighboring nodes from a structured knowledge graph can introduce additional context. If a user queries “Einstein’s theory,” related concepts such as “relativity,” “space-time,” and “mass-energy equivalence” can be added automatically.
- Historical Query Similarity: Past user queries stored in a vector database can serve as a reference. Since many queries are variations of frequently asked questions, retrieving similar past queries and appending relevant ones can enhance the current search.
- LLM-Assisted Query Rewriting: An auxiliary LLM can be used to reformulate queries, making them more explicit and contextually rich. This ensures the retrieval system gets a clearer, well-structured query.
- Hybrid Search Techniques: To mitigate the shortcomings of any single retrieval method, modern RAG systems combine multiple retrieval strategies:
- Semantic Search (Dense Vector Retrieval): Uses neural embeddings to find semantically similar documents, ideal for conceptually rich queries.
- Lexical Search (BM25, ElasticSearch, Solr): Traditional keyword-based search, which excels at retrieving exact matches, especially for short or ambiguous queries.
A common best practice in RAG implementations is to fan out the query to both retrieval methods simultaneously. The system collects the top results from both BM25 search (lexical) and dense vector search (semantic), then applies a reranker to merge and prioritize the most relevant results. This hybrid approach ensures better recall and precision, compensating for the limitations of any single retrieval method.
By incorporating query expansion and hybrid retrieval, RAG systems can significantly improve retrieval quality, reducing the dependency on users crafting perfect queries and ensuring that the generator receives the most relevant and informative context possible.
5. Hierarchical & Multi-source Retrieval
Retrieval Augmented Generation (RAG) often deals with structured and unstructured data sources across multiple domains. The challenge lies in ensuring that relevant information is retrieved accurately while maintaining the semantic integrity of the knowledge being processed. This requires sophisticated retrieval strategies that integrate multiple sources, including structured databases, enterprise documents, and web-based knowledge repositories.
5.1 The Importance of Optimal Chunking
One of the core challenges in hierarchical and multi-source retrieval is determining the optimal chunk size for indexing and retrieval. Modern large language models (LLMs) now have extended context windows, some even reaching millions of tokens, yet storing entire documents as single embeddings remains suboptimal. This is due to the semantic variability within a document; different paragraphs often convey distinct ideas, and treating them as a single vector leads to semantic dilution.
Several approaches have emerged to tackle this problem:
- Fixed-size chunking: Dividing documents into predefined segment lengths (e.g., 512 or 1024 tokens). While simple, this method may fragment coherent thoughts or merge unrelated ones.
- Recursive character-based chunking: Dynamically adjusting chunk boundaries based on sentence or paragraph structures, but still prone to suboptimal segmentation.
- AI-driven chunking: Leveraging deep learning models to identify logical breaks in the text, ensuring that each chunk represents a coherent thought unit.
One promising AI-based approach is propositional decomposition, as seen in recent research such as DenX Retrieval. This method breaks text down into atomic, self-contained knowledge units called propositions, which can then be individually indexed and embedded for retrieval. By structuring knowledge at a granular level, retrieval precision improves significantly, reducing noise and redundancy in query results.
5.2 Hybrid Search for Multi-source Retrieval
RAG systems must balance semantic search (using vector embeddings) and lexical search (keyword-based methods like BM25) to achieve optimal retrieval accuracy. Semantic search excels when queries have meaningful contextual depth, but can underperform with short or ambiguous inputs, such as homonyms.
To address this, an effective hybrid retrieval strategy is employed:
- The query is simultaneously sent to both vector search (dense retrieval) and keyword search (BM25/lexical retrieval).
- Each method retrieves its top-N most relevant results.
- A re-ranker model consolidates and ranks the results, selecting the most relevant information for the LLM’s generation process.
This approach enhances retrieval robustness, ensuring that:
- Keyword-based retrieval compensates for ambiguous or low-information queries, where vector embeddings might struggle.
- Semantic search excels in understanding complex, context-heavy queries that rely on deep relationships between words.
- The re-ranking mechanism cherry-picks the most useful results, improving answer accuracy and reducing irrelevant information.
5.3 Enterprise and Cross-domain Retrieval
Organizations increasingly require RAG systems that retrieve knowledge from multiple structured and unstructured sources, such as:
- Internal databases (e.g., SQL, NoSQL) containing structured records.
- Enterprise document repositories (e.g., PDFs, emails, reports).
- Web-based knowledge sources (e.g., Wikipedia, research papers).
Hierarchical retrieval frameworks classify and rank data sources dynamically, ensuring the most reliable and contextually relevant information is retrieved first. AI-driven chunking and hybrid search methods are essential in enabling multi-source retrieval at scale.
By combining structured hierarchy, AI-driven chunking, hybrid search, and multi-source ranking, modern RAG implementations significantly enhance retrieval accuracy, reducing hallucinations and improving response reliability.
6. Graph-RAG for Knowledge Structuring

Graph-based Retrieval Augmented Generation (Graph-RAG) is an advanced approach to organizing and retrieving knowledge by structuring information hierarchically in the form of a Knowledge Graph. Unlike traditional RAG systems that rely on a flat set of retrieved documents, Graph-RAG enhances retrieval by encoding relationships between entities and using structured representations to improve search quality. This method has been shown to significantly boost retrieval accuracy and contextual relevance in large-scale applications, though it comes at a higher computational cost.
6.1 Knowledge Graph Basics
A Knowledge Graph is a structured representation of knowledge where information is stored in the form of triplets:
- Entity 1 → Relationship → Entity 2
- Example: Fremont → is a city in → California
Each triplet forms a node-edge-node structure, which, when aggregated, creates a large graph with interconnected relationships. Traditionally, Knowledge Graphs were manually curated, with two major open-source and proprietary examples being:
- Google’s Knowledge Graph: Used to power search results, providing concise, structured answers directly in search panels.
- DBpedia: An open-source community-driven Knowledge Graph extracted from Wikipedia.
- Domain-Specific Knowledge Graphs: Used extensively in areas like medicine, finance, and law to structure domain-specific expertise.
6.2 Graph-RAG in Retrieval Augmentation
Graph-RAG leverages Knowledge Graphs in two main ways:
- Query Augmentation via Graph Expansion
- When a query is issued, the system first searches the Knowledge Graph for relevant nodes.
- It then retrieves all neighboring nodes connected to the original query entity, effectively expanding the search space.
- This method ensures that related concepts and broader contextual information are incorporated, improving retrieval precision.
- Hierarchical Knowledge Representation for Structured Summarization
- Large graphs often exhibit community structures, groups of closely connected entities related to specific topics.
- These communities can be structured hierarchically, similar to a fractal pattern:
- A domain like Artificial Intelligence contains sub-communities like Computer Vision and Natural Language Processing.
- Within NLP, further sub-communities exist for Question Answering, Summarization, etc.
- By summarizing knowledge at each hierarchical level, Graph-RAG enables retrieval at different levels of granularity, improving response coherence.
6.3 Implementation and Research Insights
Microsoft has pioneered research into Knowledge Graph-based retrieval strategies, demonstrating that:
- Large Knowledge Graphs exhibit scale-invariant properties, where community structures appear at multiple levels.
- Summarizing entities at different hierarchy levels allows queries to match not just individual documents but also broader domain-level insights.
- This structured retrieval significantly improves information retrieval quality compared to flat document indexing.
One major advantage of this approach is that structured knowledge enhances retrieval quality by prioritizing contextually relevant responses over simple keyword-based retrieval. However, the tradeoff comes in the form of computational costs and increased API call volume.
6.4 Challenges and Computational Costs
While Graph-RAG improves retrieval effectiveness, it introduces significant cost implications:
- High API usage: Constructing and utilizing Knowledge Graphs often requires querying external APIs (e.g., OpenAI), leading to large token consumption.
- Preprocessing overhead: Summarizing documents into hierarchical representations requires extensive preprocessing, increasing upfront compute costs.
- Real-world example: A research intern running Graph-RAG on a medium-sized dataset incurred a $2,500 overnight API bill, highlighting the financial cost of large-scale Knowledge Graph indexing.
Graph-RAG represents a powerful evolution in Retrieval Augmented Generation, offering improved retrieval accuracy and structured knowledge organization. However, it comes with significant tradeoffs in terms of preprocessing effort and computational expense. Organizations implementing Graph-RAG must carefully balance retrieval quality with the associated infrastructure and API costs to determine its feasibility for their specific use cases.
7. Agentic RAG for Adaptive Retrieval

Agentic Retrieval-Augmented Generation (Agentic RAG) introduces an adaptive approach to retrieval by leveraging AI-driven agents that dynamically allocate computational resources based on the complexity and nature of a query. Unlike traditional RAG models that apply a uniform retrieval and generation process for all queries, Agentic RAG optimizes inference by selectively engaging retrieval pipelines, query expansion techniques, and hallucination mitigation steps depending on the query’s characteristics.
7.1 How Agentic RAG Works
- Query Inspection & Routing:
- Upon receiving a query, specialized AI agents analyze its content and intent.
- If the query is straightforward (e.g., “What is the capital of California?”), it bypasses retrieval and is answered directly by the language model.
- For domain-specific queries (e.g., finance, technology, medicine), the query is directed to an appropriate knowledge base or retrieval pipeline.
- Adaptive Query Processing:
- If the query is ambiguous or malformed, an agent refines or expands it using techniques such as LLM-assisted rewriting or query decomposition.
- This ensures that retrieval components receive well-structured input, improving the relevance of retrieved documents.
- Multi-Stage Retrieval & Validation:
- The system retrieves information from relevant sources, whether structured databases, vector stores, or web-based APIs.
- Instead of relying solely on a single retrieval step, agentic mechanisms allow iterative refinement, agents assess retrieved results, verifying factual accuracy and coherence.
- Some implementations incorporate adversarial agent debates, where agents cross-check retrieved content against independent sources before confirming its reliability.
- Decision-Making & Final Response Generation:
- Once retrieval and validation are complete, the response is synthesized, ensuring it is grounded in factual evidence.
- If gaps or inconsistencies are detected, the process may iterate before finalizing an answer.
7.2 Benefits of Agentic RAG
- Improved Accuracy: By dynamically adjusting retrieval strategies and verifying responses, Agentic RAG reduces hallucinations and enhances factual grounding.
- Domain-Specific Adaptability: It tailors retrieval behavior based on context, ensuring legal, medical, or financial queries retrieve from the most relevant sources.
- Query Optimization: Adaptive expansion and restructuring enhance retrieval efficiency, especially for complex or ambiguous queries.
7.3 Tradeoffs & Challenges
- Increased Latency: Multiple processing steps and iterative validation significantly increase response time, making Agentic RAG unsuitable for low-latency applications.
- Higher Computational Cost: The additional reasoning steps require more inference compute, making it expensive compared to traditional RAG approaches.
- Complex Implementation: Designing intelligent agents that effectively route queries, validate facts, and balance retrieval costs adds architectural complexity.
7.4 Where Agentic RAG Excels
In high-stakes applications where accuracy is paramount, such as medical diagnosis, legal research, and scientific discovery, Agentic RAG justifies its computational overhead by delivering high-confidence, well-supported responses. These domains prioritize correctness over speed, making Agentic RAG a powerful strategy for enterprise and critical-use AI deployments.
8. Key Research Findings on RAG Performance
Research on Retrieval-Augmented Generation (RAG) has sought to identify best practices, evaluate its efficiency, and understand the factors influencing its performance. A key study in this domain conducted an extensive benchmarking analysis to assess the impact of various RAG techniques on Large Language Model (LLM) responses. While there are differing opinions on the study’s conclusions, it raises important research questions that help frame ongoing debates about RAG optimization.
8.1 Five Key Research Questions in RAG Evaluation
- How does RAG affect LLM efficiency and response quality?
- The study analyzed whether integrating retrieval components consistently improves response accuracy across diverse tasks.
- While RAG reduces hallucinations and enhances factual consistency, its effectiveness depends on retrieval quality, document relevance, and chunking strategy.
- Does LLM size significantly impact RAG performance?
- Larger models generally benefit more from RAG due to better reasoning and synthesis capabilities.
- However, smaller models with well-optimized retrieval pipelines can achieve competitive performance with significantly lower computational costs.
- The tradeoff between model size and retrieval quality remains an open question, particularly in cost-sensitive applications.
- What are the optimal chunking strategies for retrieval?
- Chunking impacts retrieval quality, as overly large chunks dilute relevance while excessively small chunks fragment context.
- AI-driven chunking techniques (e.g., propositional decomposition, structured chunking) improve information retrieval by balancing context retention and retrieval precision.
- The study found that optimal chunking varies by domain, with legal and medical applications benefiting from structured hierarchical chunking.
- What role does retrieval stride play in RAG effectiveness?
- The overlap between retrieved document segments (retrieval stride) influences information redundancy and response coherence.
- Too much overlap increases retrieval latency without additional benefit, while too little overlap risks missing relevant context.
- Finding the right retrieval stride is crucial for maintaining balance between response completeness and computational efficiency.
- How does RAG perform in multilingual retrieval?
- RAG’s effectiveness varies significantly across languages due to differences in corpus quality, retrieval effectiveness, and LLM training data.
- The study found that languages with rich retrieval corpora (e.g., English, Chinese) benefit more from RAG, while low-resource languages struggle with retrieval gaps.
- Techniques such as cross-lingual embeddings and translation-assisted retrieval improve performance in multilingual settings.
8.2 Diverging Opinions & Practical Insights
- While the study presents these findings as generalizable insights, some researchers challenge its conclusions, particularly regarding the impact of chunk size, knowledge base scale, and query expansion.
- Practical implementations suggest that corpus quality, domain-specific retrieval techniques, and adaptive chunking strategies play a larger role than the study implies.
- The debate underscores the need for domain-specific benchmarking and continued refinement of retrieval techniques tailored to real-world applications.
Overall, these research findings provide a foundation for optimizing RAG, but practical considerations, including data quality, retrieval methodology, and computational constraints, must be factored into real-world deployments.
9. Disagreements & Practical Insights
Recent research into Retrieval-Augmented Generation (RAG) has introduced novel methodologies and benchmarks to assess and improve RAG setups. The study in question claims to be the first to empirically investigate aspects such as query expansion, contrastive in-context learning demonstration, multilingual knowledge bases, and focused mode RAG. While the researchers are indeed the creators of contrastive in-context learning demonstration and focused mode RAG, the claim that multilingual RAG has never been studied empirically is surprising, as prior work has explored related areas. Nevertheless, their benchmarking efforts provide valuable insights into the effectiveness of these techniques.
9.1 Query Expansion and Re-ranking
One of the central techniques analyzed is query expansion. Inspired by established principles in information retrieval, this approach broadens the initial search by generating multiple query variants and subsequently refining the results through re-ranking. The study employs FLAN-T5, a full encoder-decoder Transformer model, to generate expanded query variants. This process generates a diverse candidate set of results, which is then ranked using a standard retriever, typically a BERT-based model. The ranker evaluates the relevance of each retrieved document to the expanded query, ensuring that the final selection maintains high contextual relevance. While the use of an LLM for query expansion is not novel, the study systematically benchmarks its impact, providing empirical validation for this approach.
9.2. Retrieval Methods and Ranking
The retrieval module in the study employs dense vector search using a Sentence Transformer model, specifically the one introduced in Reimers & Gurevych (2019). Unlike hybrid search, which combines semantic embeddings with keyword-based retrieval, this study relies solely on dense retrieval. While effective, hybrid search approaches that incorporate sparse retrieval (e.g., BM25) might yield better performance in certain contexts by capturing both semantic meaning and exact keyword matches. The study does not explore this avenue, leaving room for further investigation.
9.3. RAG Performance Findings and Disagreements
One of the more controversial findings pertains to model size. The study compares the performance of Mistral 7B and a larger 45B-parameter instruction-tuned model, concluding that the latter significantly outperforms the smaller model, particularly on truthfulness benchmarks. This aligns with the general intuition that larger models exhibit better reasoning capabilities. However, practical experience suggests that beyond a certain threshold (typically 30B-45B parameters), gains diminish, making further scaling less cost-effective. This aligns with previous findings on logarithmic improvements in model performance.
Prompt sensitivity is another critical issue highlighted. The study finds that even minor modifications to prompts can drastically alter model outputs, reinforcing the well-documented instability of LLMs. Adversarial prompts consistently degrade performance, a known challenge in deploying RAG systems in real-world applications. While this finding is not novel, its empirical validation adds weight to the argument for robust prompt engineering.
9.4 Disagreement on Chunking Strategies
One of the most surprising findings is the claim that chunk size has minimal impact on retrieval performance. The study tests various chunk sizes and finds only minor variations across different metrics. This contradicts practical experience, where chunking strategies play a crucial role in optimizing retrieval. Effective chunking improves contextual coherence, prevents information loss, and enhances the retriever’s ability to match relevant documents. The discrepancy likely stems from corpus-specific factors; different datasets may respond differently to chunking variations. This suggests that further research is needed to generalize the findings across diverse knowledge bases.
9.5 Conclusion
While the study provides valuable empirical benchmarks for RAG, some of its conclusions remain contentious. Query expansion and ranking methodologies align with established best practices, and findings on prompt sensitivity and model scaling reinforce prior knowledge. However, the study’s claims about chunk size impact require further scrutiny, as real-world implementations often find significant performance differences based on chunking strategies. Future research should explore the interplay between retrieval strategies, corpus composition, and chunking methodologies to refine best practices for deploying RAG systems at scale.